幸运的是,老吴给我介绍了一位Python大牛Richard Penman(澳大利亚人,开源项目webscraping的作者,http://code.google.com/p/webscraping/ ),有他的指点下我会学的很快。
Richard Penman给我布置了一个作业:
将menupalace.com网站上所有餐馆的相关信息抓取下来,存入csv中。
需要抓取的数据有:
-restaurant name
-address
- city
- state
- country
- website
任务的难点在于html的解析,我是通过正则匹配来实现的。
最终代码如下,由于要给Richard看,所以注释只能用e文了:
哎,可恶的编辑器,代码格式全乱了,缩进都消失了。
附上源文件:File: Click to Download
#Practice of scraping web data
#by redice 2010.10.26
#scraping.py
import re
#Fetch the all string matched. Return a list.
def regexmatch(rule,str):
'''Fetch the all string matched. Return a list.'''
p = re.compile(rule)
return p.findall(str)
#end def regexmatch
import urllib2
#Fetch the target html
def gethtml(url):
'''Fetch the target html'''
try:
response = urllib2.urlopen(url)
return response.read()
except URLError, e:
if hasattr(e, 'reason'):
print 'Failed to reach a server.'
print 'Reason: ', e.reason
elif hasattr(e, 'code'):
print 'The server couldn't fulfill the request.'
print 'Error code: ', e.code
#end def gethtml
#decodeHtmlEntity
def decodeHtmlEntity(s) :
'''decodeHtmlEntity'''
result = s
entityRe = '(&#(\d{5});)'
entities = re.findall(entityRe, s)
for entity in entities :
result = result.replace(entity[0], unichr(int(entity[1])))
result=result.replace(' ',' ')
return result
#end def decodeHtmlEntity
#Fetch menupalace.com's html
html=gethtml('http://menupalace.com')
print 'Fetching html from http://menupalace.com ...'
# fetch the two country list
rule = r'''<table width="100%" border="0" cellspacing="0" cellpadding="0" class="n_table">([sS]*?)</table>'''
result = regexmatch(rule,html)
#final result
dining_db = []
for item in result:
#fetch city name
r = regexmatch(r'''<img src="images/MP_logoBullet.jpg" width="17" height="17" align="top" />([sS]*?)</td>''',item)
if len(r)>=1:
country=r[0].strip()
#fetch link
r=regexmatch(r'''<a href="([ S]*?)" class="smallP">([ S]*?)</a>''',item)
for n in r:
#city name
city=n[1].strip()
#fetch details
if len(n[0])>7:
html=gethtml(n[0])
print 'Fetching html from ',n[0],' ...'
r1=regexmatch(r'''<table width="100%" border="0" cellspacing="0" cellpadding="0">([sS]*?)</table>''',html)
for i in r1:
#name r2[0]
r2=regexmatch(r'''<span id="ctl00_ContentPlaceHolder1_S*side_CompanyName">([ S]*?)</span>''',i)
#address r3[0]
r3=regexmatch(r'''<span id="ctl00_ContentPlaceHolder1_feature_S*side_Address">([ S]*?)</span>''',i)
#website r4[0]
r4=regexmatch(r'''<span id="ctl00_ContentPlaceHolder1_feature_S*side_Website">([ S]*?)</span>''',i)
if len(r2)>0 and len(r3)>0 and len(r4)>0:
dining = {}
dining['name'] = decodeHtmlEntity(r2[0])
dining['address'] = decodeHtmlEntity(r3[0])
dining['city'] = city
dining['state'] = city
dining['country'] = country
dining['website'] = r4[0]
dining_db.append(dining)
if len(r2)==0 and len(r3)==0 and len(r4)==0:
#name r2[0]
r2=regexmatch(r'''<!-- InstanceBeginEditable name="featuredRestaurantName" --><a [ S]*?><img [ S]*?/> ([ S]*?)</a><!-- InstanceEndEditable -->''',i)
#address r3[0]
r3=regexmatch(r'''<!-- InstanceBeginEditable name="featuredRestaurantAddress" --><p class="featuredRestP">([ S]*?) </p><!-- InstanceEndEditable -->''',i)
#website r4[0]
r4=regexmatch(r'''<!-- InstanceBeginEditable name="featuredRestaurantURL" --><a [ S]*?>([ S]*?)</a><!-- InstanceEndEditable -->''',i)
if len(r2)>0 and len(r3)>0 and len(r4)>0:
dining = {}
dining['name'] = decodeHtmlEntity(r2[0])
dining['address'] = decodeHtmlEntity(r3[0])
dining['city'] = city
dining['state'] = city
dining['country'] = country
dining['website'] = r4[0]
dining_db.append(dining)
#print and save the final result
import csv
cf = open("scraping_result.csv", "w")
writer = csv.writer(cf)
writer.writerow(['name','address','city','state','country','website'])
for item in dining_db:
#print item['name'],item['address'],item['city'],item['state'],item['country'],item['website']
rlist=[]
rlist.append(item['name'])
rlist.append(item['address'])
rlist.append(item['city'])
rlist.append(item['state'])
rlist.append(item['country'])
rlist.append(item['website'])
writer.writerow(rlist)
cf.close()
print 'The result has been saved into scraping_result.csv!'
说明:由于state(州)需要通过一个city到state的字典来查询得到,我没有这个字典,暂时就用city来填充。
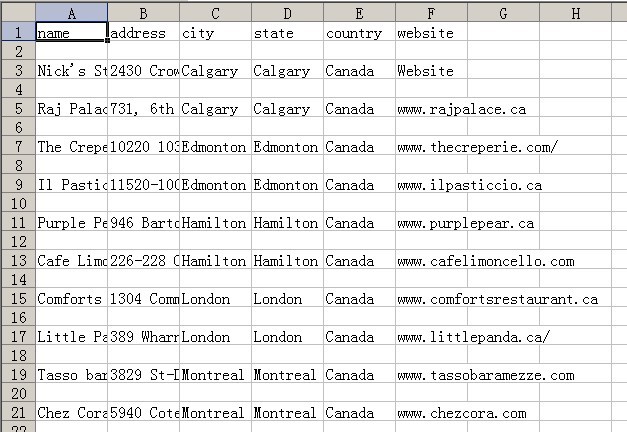
程序运行截图:
Richard看了代码后建议我尝试用xpath进行XML解析。
经查询得知:XPath 是一门在 XML 文档中查找信息的语言。Python的lxml库支持xpath。 打算随后用xpath重写本例的程序。
呵呵,谢谢
VaTG790i.最好的<a href=http://www.kyfei.com>网站推广软件</a>,
非常好
....................
;ui;普i;uighur;ui;ui;个
在unix网络编程中看到了关于TCP/IP的一些内容,我感觉还是写的不够。正在下载中,一定
下载地址呢