利用的是pyPdf库的PDF页面合并(叠加)功能(merging documents page by pag),即将原始PDF页面与水印PDF页面进行叠加。
直接上码:
# coding: utf-8
# pdf_watermark.py
import os
# http://pybrary.net/pyPdf/
from pyPdf import PdfFileWriter, PdfFileReader
# http://www.reportlab.com
from reportlab.pdfgen import canvas
def create_watermark(content):
"""创建PDF水印模板
"""
# 使用reportlab来创建一个PDF文件来作为一个水印文件
c = canvas.Canvas('watermark.pdf')
c.setFont('Courier', 10)
# 设置水印文件
c.saveState()
c.translate(300, 15)
# 水印文字
c.drawCentredString(0, 0, content)
c.restoreState()
# 保存水印文件
c.save()
pdf_watermark = PdfFileReader(file('watermark.pdf', 'rb'))
return pdf_watermark
def add_watermark(pdf_file, pdf_watermark, output_dir='output', max_page=5):
"""给指定PDF文件文件加上水印
pdf_file - 要加水印的源PDF文件
pdf_watermark - PDF水印模板
max_page - 加水印的最大页数
"""
pdf_output = PdfFileWriter()
input_stream = file(pdf_file, 'rb')
pdf_input = PdfFileReader(input_stream)
# PDF文件被加密了
if pdf_input.getIsEncrypted():
print '该PDF文件被加密了.'
# 尝试用空密码解密
try:
pdf_input.decrypt('')
except Exception, e:
print '尝试用空密码解密失败.'
return False
else:
print '用空密码解密成功.'
# 获取PDF文件的页数
pageNum = pdf_input.getNumPages()
# 给每一页打水印
for i in range(pageNum):
page = pdf_input.getPage(i)
if i < max_page:
# 只给前max_page页加水印
page.mergePage(pdf_watermark.getPage(0))
pdf_output.addPage(page)
# 最后输出文件
output_stream = file(os.path.join(output_dir, os.path.basename(pdf_file)), 'wb')
pdf_output.write(output_stream)
output_stream.close()
input_stream.close()
return True
if __name__ == '__main__':
# 创建水印文件
pdf_watermark = create_watermark('www.site-digger.com')
add_watermark('HLMP_6405_J0011.pdf', pdf_watermark)
可以分享的经验是:
不少PDF文件被加密了,需要先解密才能加上水印,幸运的是好多密码直接是空的。
上述程序在处理一个PDF前会先判断其是否被加密了,如果是则尝试用空密码进行解密。
无图无真相:
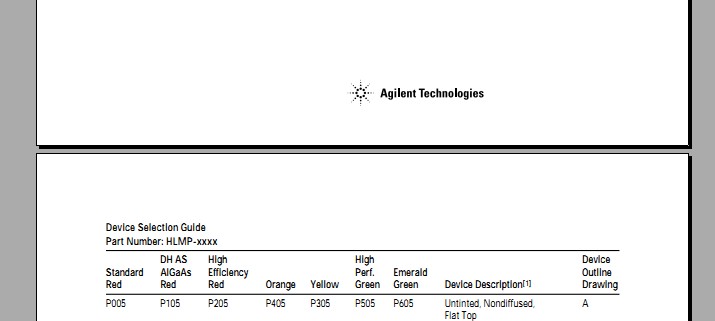
这是原始的PDF

这是水印PDF
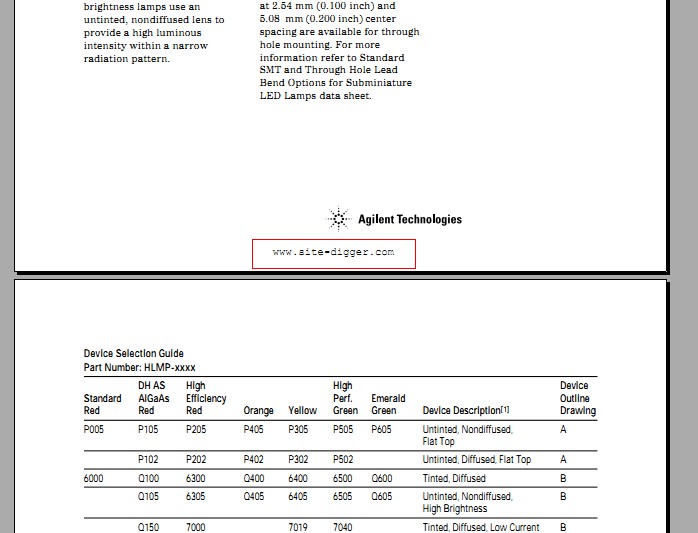
这是处理后(叠加)的效果
呵呵,谢谢
VaTG790i.最好的<a href=http://www.kyfei.com>网站推广软件</a>,
非常好
....................
;ui;普i;uighur;ui;ui;个
在unix网络编程中看到了关于TCP/IP的一些内容,我感觉还是写的不够。正在下载中,一定
下载地址呢