今天Pythoner群(103441184)里面有人提了一个大意如下的问题:
http://127.0.0.1:8000/test/ 对应的处理过程如下
def test(request):
response = HttpResponse('This is content!', \
content_type='application/octet-stream')
response['Content-Disposition'] = 'attachment; filename=test.txt'
return response
在各种浏览器中访问http://127.0.0.1:8000/test/都能下载到文件名为test.txt的文件,但是用迅雷却始终下载到名为index.html的文件。
于是他怀疑是不是自己的程序什么地方有问题。
我的分析:
1)浏览器能够识别文件名为test.txt那它肯定是读取了HTTP应答头中的Content-Disposition字段的值。
2)做一个实验,测试迅雷在确定文件名为index.htm之前与服务器是否有过交互。
如果有交互,那么迅雷也完全能从Content-Disposition头中读取到文件名,如果没有交互那说明迅雷完全是根据要下载的URL确定的文件名。
测试结果如下:
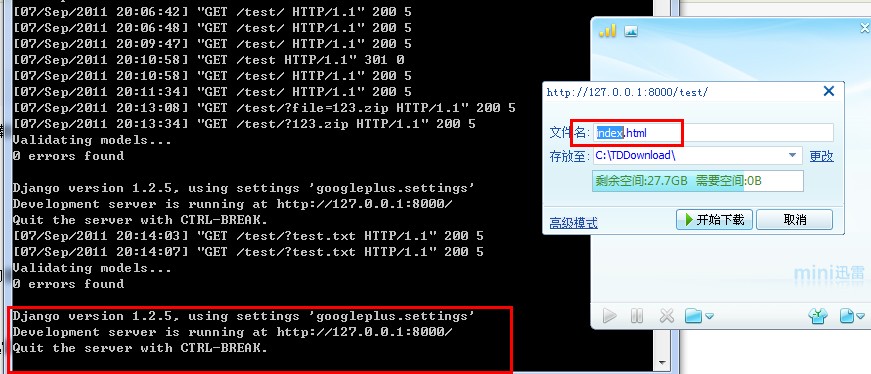
图1:左侧的CMD窗口会将所有的请求显示出来。看了在迅雷确定下载文件名为index.html之前与服务端并没有任何交互。
因此可以断定它完全是根据URL来确定的文件名。
那为什么会是index.html呢?
因为http://127.0.0.1:8000/test/这个路径最终以目录名结束,迅雷找不到文件名就默认文件名为index.html,这与服务端的设置以及程序都没有任何关系。
完全是迅雷自己决定的。
再看一张截图:
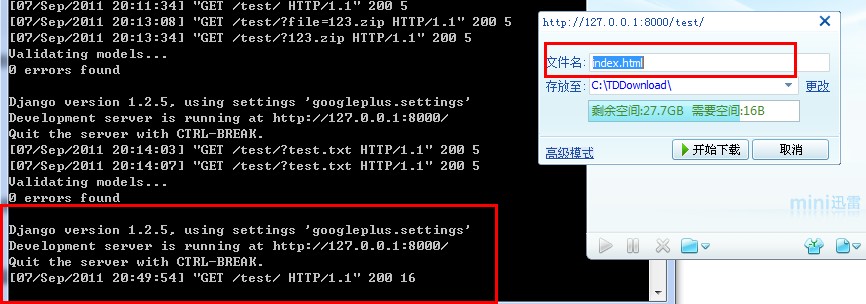
图2:在文件名出现后大概1S左右,左侧CMD窗口显示出了一次请求,这次请求是迅雷用来获取文件大小的。迅雷窗口上显示出了需要空间16B。
进一步验证:
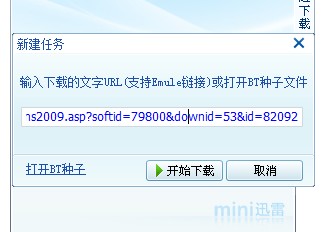
在迅雷中新建任务下载如下的URL:
http://www.xdowns.com/soft/xdowns2009.asp?softid=79800&downid=53&id=82092
新建任务(如下图所示):
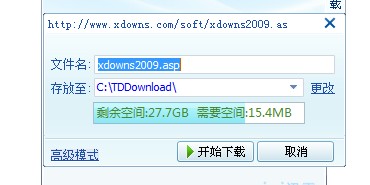
点击“开始下载”(如下图所示),显示的文件名为xdowns2009.asp,这时上述URL的最终文件名。
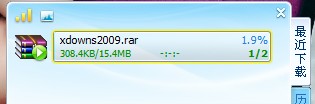
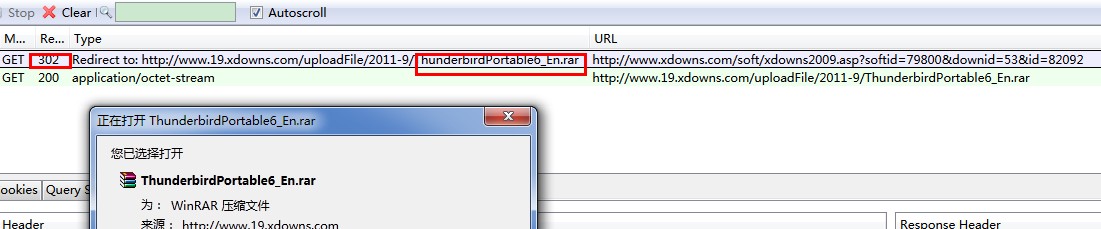
结论:
迅雷的下载文件名默认(非人为指定)是根据URL中的文件名确定的,如果有30X跳转,文件名还与跳转后的URL有关系。
HTTP头的Content-Disposition字段不会影响到迅雷的下载文件名。为什么会这样?这完全是迅雷开发团队自己决定的,他们有这个自由。
呵呵,谢谢
VaTG790i.最好的<a href=http://www.kyfei.com>网站推广软件</a>,
非常好
....................
;ui;普i;uighur;ui;ui;个
在unix网络编程中看到了关于TCP/IP的一些内容,我感觉还是写的不够。正在下载中,一定
下载地址呢