xvfb启动PyQt4程序报如下错误: Unable to load library icui18n Cannot load library icui18n: (libicui18n.so.48: cannot open shared object file: No such file or directory) 解决方法: sudo apt-get install libicu48 参考: https://forums.virtualb
在QWebView中使用下面代码 # 在QWebView中使用下面代码cookies = []for citem in self.page().networkAccessManager().cookieJar().cookiesForUrl(QUrl('http://flight.qunar.com')): cookies.append('%s=%s' % (citem.name(), citem.value())) cookies = com
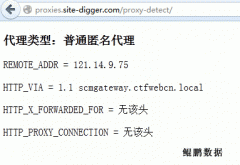
在Web数据采集中为了避免被服务器封锁而通过代理下载的情况很常见。但是,并非所有的代理都适合于Web数据采集。下面是鲲鹏数据的技术人员给出的说明。 根据HTTP代理的匿名性可以将其分为以下几种: 1. 透明代理(Transparent Proxies) 目标服务器能够检测到
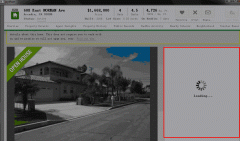
使用webkit遇到一个非常诡异的问题,同样的代理(username:password@host:port格式),在FireFox下载使用正常,可以完整地加载目标页面。 而使用webkit,页面上总是有一个区域加载不了(如下图),去掉代理就正常了。刚开始怀疑是网站检测了User-agent,但是
1)安装zilib apt-get install zlib1g-dev 2)安装sqlite3 wget http://www.sqlite.org/sqlite-3.5.6.tar.gz tar -xzvf sqlite-3.5.6.tar.gz cd sqlite-3.5.6 ./configure --disable-tcl make make install 3)安装python2.7 wget http://www.python.org/ftp
我想到了两种方案: 1)从whois查询网站上抓取,例如http://whois.chinaz.com。 2)从whois命令行查询工具的结果中获
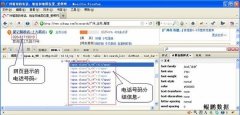
说明:同事Jamp写的,挺不错的。 原文地址: http://www.site-digger.com/html/articles/20110709/15.html 最近有客户咨询能否抓取爱帮网(http://www.aibang.com/)上的数据,主要是因为爱帮网的电话号码是经过加密处理的,常规的方法获取不到真实的电话号
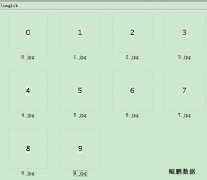
验证码识别,一直是我想实现的。今天终于实现了一个简单的。 // 转载请注明出处 鲲鹏数据 http://www.site-digger.com 陕西移动网厅: http://www.sn.10086.cn/ 验证码生成链接: https://sn.ac.10086.cn/SSO/servlet/CreateImage 验证码示例: 该验证码较为
来源: 鲲鹏数据 http://www.site-digger.com/html/articles/20110604/13.html 项目中经常需要将完整的美国地址(例如,6200 20th Street, Vero Beach, FL 32966)进行细分: address:6200 20th Street City:Vero Beach State: FL Zip code:32966 下面给出一
原文地址: http://dcortesi.com/2008/05/28/google-ajax-search-api-example-python-code/ Google Web Search API的文档: http://code.google.com/intl/zh-CN/apis/websearch/docs/reference.html#_intro_fonje For whatever reason, there arent many exa
指向同一资源的URL表现形式可能存在差异,例如,下面三个URL实际上指向的是同一资源: http://www.REDICECN.com/ http://www.redicecn.com http://www.redicecn.com/tools/../ 对于爬虫来说,合理的处理方式是将上述三个表现不同URL视为相同的URL。 下面给出
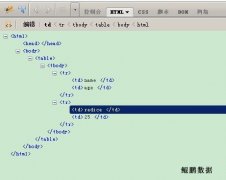
在数据采集时,处理不规范的HTML页面是件令人头疼的事。因为不规范的HTML页面往往会引起xpath解析失败,造成得不到正确的数据。 了解Firebug的人都知道,它的HTML视图下有一个巧妙的功能,能够自动修复不规范的HTML,以规范的形式展现。 例如,如下的一个不
很好 。。
呵呵,谢谢
非常好
....................
在unix网络编程中看到了关于TCP/IP的一些内容,我感觉还是写的不够。正在下载中,一定
下载地址呢
谢~~